AI 的回答是正確的嗎?
分享一篇 Search Engine Journal 的文章 —— 「為何國際 SEO 需要全球知識完整性策略」,分享給所有有做多語系跨國際企業的網站。
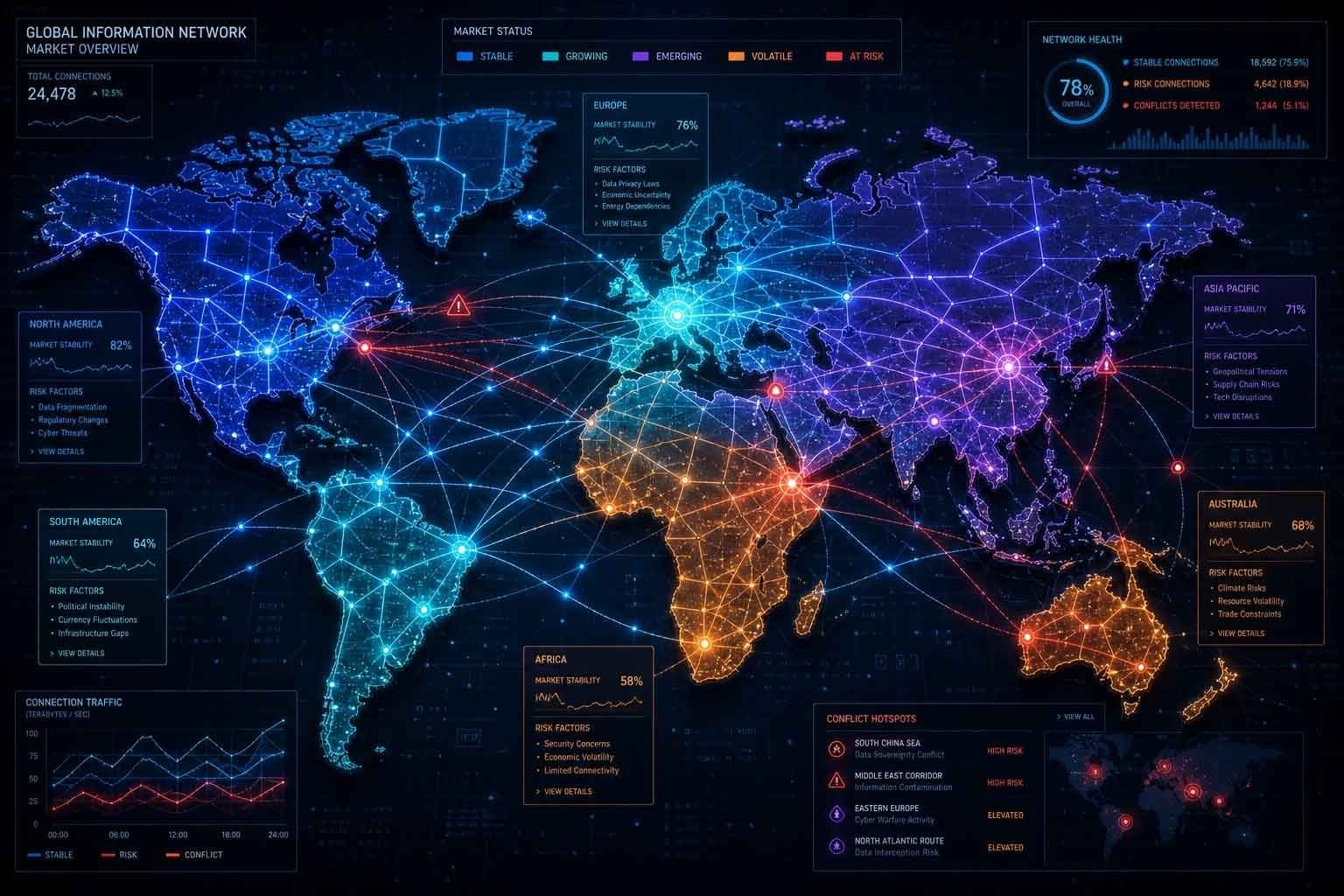
如果有人問 ChatGPT「這個藥在我的國家核准了嗎」,它給的答案,到底是從哪一個市場的網頁學來的?
這不是危言聳聽。Search Engine Journal 專欄作者 Bill Hunt 在他最新的文章裡,點出一個很多跨國企業還沒意識到的風險:當 AI 搜尋系統去抓取你全球各地的網站內容時,它根本不在乎你公司內部畫的市場界線。美國團隊管美國站、德國團隊管德國站,這種分工在你的組織圖上很清楚,但在 AI 眼裡,看到的只是一堆實體、段落、文件、產品名稱、宣稱跟關係,沒有國界。
過去二十年,國際 SEO 在做的事情很單純:用 hreflang、canonical 標籤、在地化網址,確保「對的頁面」出現在「對的市場」。但現在 ChatGPT 週活躍用戶已經衝到 9 億,Google 的 AI Overview 據統計影響了將近一半的追蹤搜尋查詢。資訊在使用者真正點進你的網站之前,就已經被 AI 抓取、解讀、合成過一輪了。
問題不再是「哪個頁面該排第一」,而是「哪個答案能在 AI 的合成過程裡活下來,而且還是對的」。
建議:若你的團隊正在規劃 AI 搜尋優化(GEO),建議先盤點你目前所有市場的網站內容,看看有沒有「同一件事,說法卻不一樣」的狀況。
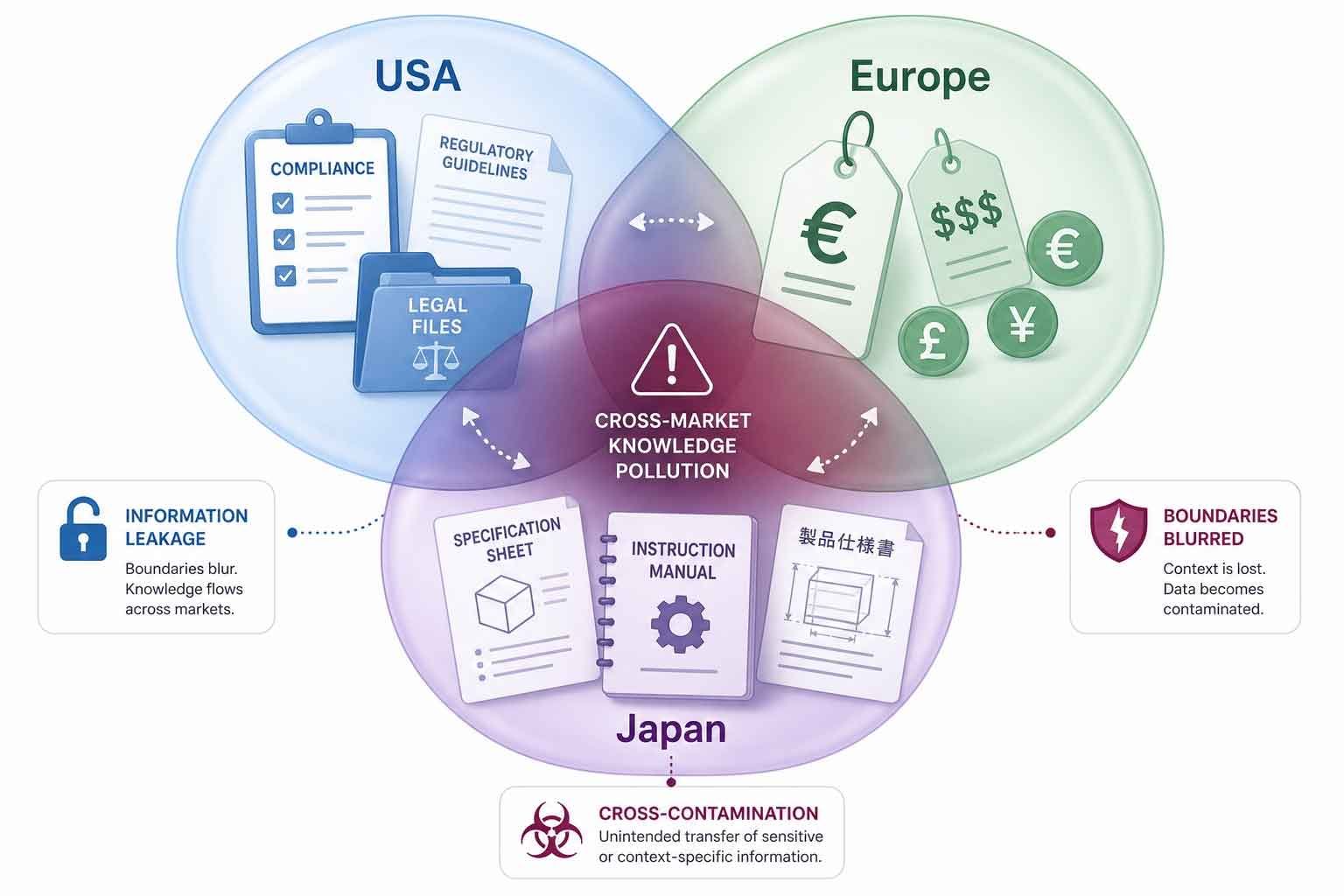
跨市場知識污染:你的網站正在「互相汙染」
Bill Hunt 提出一個很犀利的新詞 —— 跨市場知識污染(Cross-Market Knowledge Contamination)。簡單說,就是當不同市場的內容被 AI 一起吃進去、做語意壓縮之後,原本各自有上下文、有適用範圍的資訊,被混在一起、解讀錯誤,或是直接端出來,卻完全沒提到「這個答案其實只適用於某個地區」。
他舉了一個讓人冒冷汗的例子:一家藥廠在 40 個市場營運,某個治療適應症在美國核准了,但德國根本沒核准。傳統搜尋引擎靠 hreflang,還能正確排出對的那一頁。但 AI 系統可能直接把兩個市場的資料合成成一個答案 —— 這時候,問題已經不是「頁面排序錯誤」,是「答案本身就是錯的」,而且還可能牽涉法規。
更麻煩的是,企業常用的 Geo-IP 阻擋手法,對 AI 爬蟲根本沒用。因為這些爬蟲多半是從美國的中央化雲端伺服器發出請求,你在前端設的地區限制,擋不住背後的資料抓取。Bill Hunt 直接講:如果沒有一套真正內建在網站架構裡的資料治理策略,你的全球各地網站,會在模型的高維向量空間裡,自己把自己「汙染」掉。
這已經不只是 SEO 問題了。是品牌、法規遵循、客戶體驗、企業治理,一次到位的問題。
為什麼只做表面的 GEO 技巧不夠用
現在很多 AI 優化建議都停留在頁面層級:加 FAQ、做內容摘要、改用對話式標題、補 schema、做一個 llms.txt。這些招數可能多少有幫助,但說真的,它們解決不了企業真正的問題。
FAQ 寫得再漂亮,也修不好互相矛盾的產品資料。schema 標記補得再完整,也彌補不了一個過時的地區頁面。llms.txt 檔案,更不可能阻止 AI 系統在你龐大的數位足跡裡,撞見彼此衝突的市場宣稱。
真正的問題不是「這頁有沒有格式化方便 AI 擷取」,而是「這家公司,到底有沒有在治理 AI 系統一開始吃進去的那些資訊」。
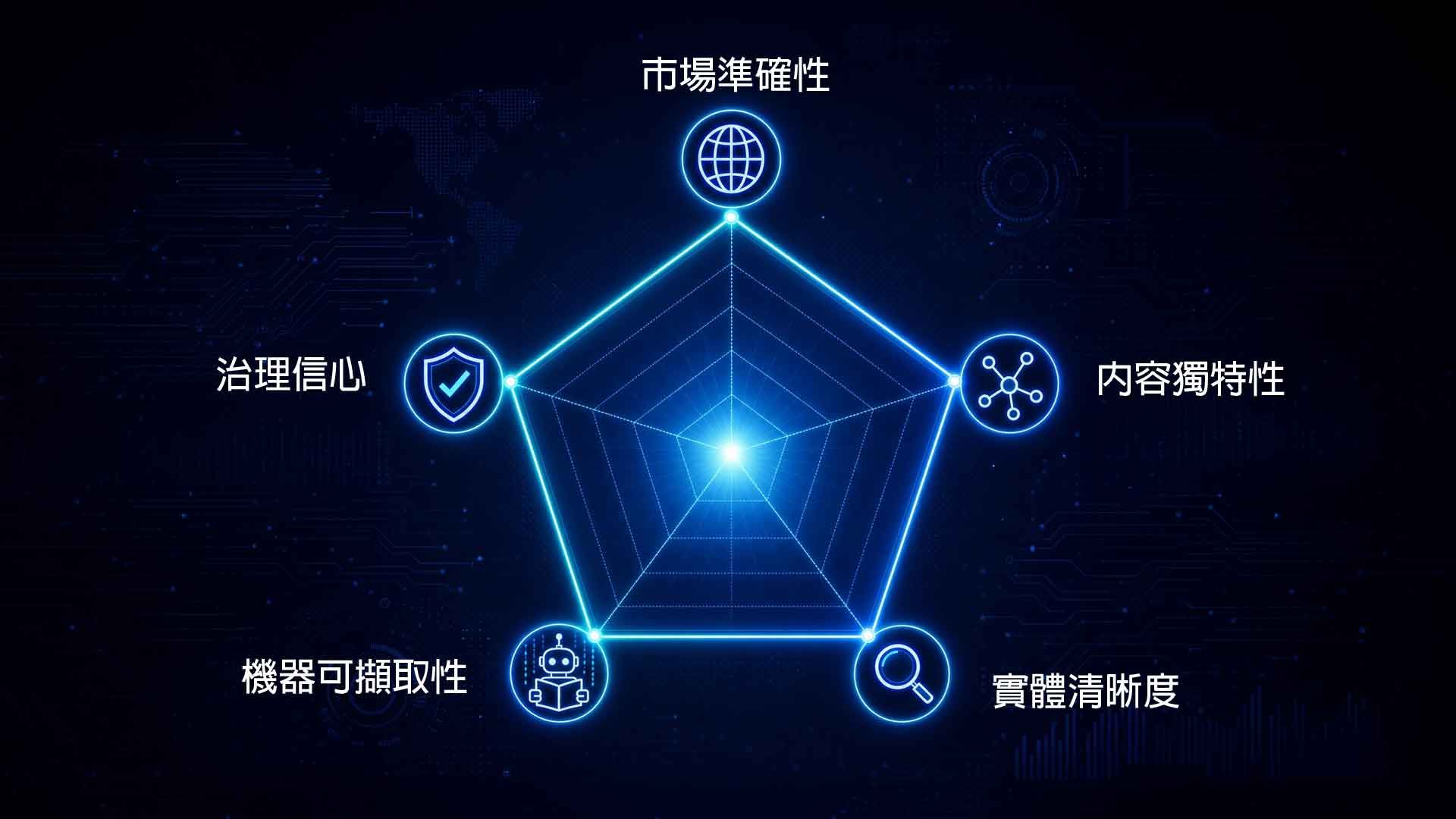
全球知識誠信矩陣(GKIM):五個檢核維度
Bill Hunt 提出一個叫做「全球知識誠信矩陣」(Global Knowledge Integrity Matrix, GKIM)的框架,讓團隊用五個維度去檢視每個市場、每個產品、每種內容類型:
- 市場準確性:
這個資訊對於使用者所在的國家、語言、貨幣、法規、產品可用性、客戶期待,是正確的嗎? - 實體清晰度:
產品、地點、服務、人物、品牌、組織,在頁面、schema、資料 feed、內部系統裡,有沒有被清楚識別並串連起來? - 內容獨特性:
每個地區頁面是真的提供當地專屬的價值,還是只是把別的市場內容翻譯一遍而已? - 機器可擷取性:
搜尋引擎跟 AI 系統,能不能輕鬆判斷出答案、來源、日期、適用範圍跟關係? - 治理信心:
有沒有明確的負責人、審核週期、核准流程,以及資訊一旦變動時的升級處理路徑?
很多公司管理內容的方式,其實就是一堆頁面分散給不同人負責。但 AI 系統看的不是頁面,它看到的是事實、實體、關係跟宣稱。GKIM 提供的,是一套讓每個地區能「以自己的脈絡被理解」的治理框架,而不是把每個地區都當成「全球範本的某個變化版」。
落地怎麼做:從風險最高的地方先動手
一套扎實的全球知識誠信計畫,應該從業務與法規風險最高的地方開始:產品頁、定價頁、醫療或財務相關宣稱、法律揭露事項、門店或地點頁面、客服內容、PDF 文件,以及地區性的到達頁。
具體流程大概是這樣:
- 盤點同一個產品、宣稱或服務,在不同市場各出現在哪些地方
- 找出彼此衝突或已經過時的資訊
- 為每個市場指定「誰是權威來源」
- 強化在地訊號,像是貨幣、地址、法規、計量單位、產品可用性、核准過的宣稱
- 把內容結構化成清楚的答案區塊,標明日期、來源、所有權
- 用 schema、內部連結、實體 ID、資料 feed、CMS 欄位把頁面串起來
- 實測 AI 系統是否真的擷取出對的、符合該市場的答案
- 建立治理工作流程,確保資訊一更新,所有相關的資產都會跟著同步
而其中最關鍵的改變,是「所有權」這件事。如果一個答案,每個人都覺得自己有份,那其實就等於沒人真正負責。
企業也許需要一個新角色:答案副總(VP of Answers)
Bill Hunt 認為,大型組織或許需要一個新職位——可以稱之為「答案副總」(VP of Answers)。職稱本身不重要,重點是「誰要扛這個責任」。這個人的任務,是確保公司在所有地方講的都是同一套話,而且 AI 系統抓到的是正確版本的資訊。
這個角色不會取代 SEO、內容、法務或工程團隊,而是把這些團隊串起來,確保公司的公開知識在搜尋引擎、AI 系統、各地區網站、結構化資料、資料 feed 跟內部平台之間,是一致、對齊、能被使用的。
寫在最後
國際 SEO 沒有死,也不需要再發明一個新的縮寫詞,它需要的是被納入更大的企業治理體系裡。真正能在 AI 搜尋時代勝出的公司,不會是那些一直追逐最新 GEO 技巧的人,而是真正理解「網站早就不只是行銷資產,而是公開的知識基礎設施」的人。在一個答案被層層合成的搜尋環境裡,沒有被管理好的全球知識,本身就是一種負債。
如果你的公司在多個市場營運,現在或許是時候問自己一句:當 AI 幫你的客戶回答問題時,它講的,真的是「你想讓他知道的那個版本」嗎?
