
llms.txt 到底對 GEO / AEO 有沒有用
最近幾天,看到 Search Engine Journal 的幾篇關於「LLMS.txt」的文章,蠻有趣的,在這裡整理分享出來!
你做了 llms.txt,然後呢?
去年底,「llms.txt」這個概念火了。
概念很直觀:既然 AI 會爬你的網站,你就放一個專門給 AI 讀的說明檔案,告訴它你是誰、你的網站有什麼、AI 代理應該怎麼使用你的內容。聽起來合理,所以很多網站跟著做了。
然後 Ahrefs 在 2026 年 5 月公布了數據。
在 38,000 個擁有有效 llms.txt 的網域中,97% 在整個月份收到零請求。 沒有機器人來讀,沒有人類來看,就這樣靜靜躺在伺服器裡。
我看到這個數字的時候,腦子裡第一個反應是:好,那現在怎麼辦?
這篇文章整理了三個你需要知道的現實——不是要讓你放棄做 AI 優化,而是要讓你把時間花在真正有效的地方。
現實一:llms.txt 的問題,跟 Meta Keywords 一模一樣
Google 的 John Mueller 說得很直接:llms.txt 屬於網站「自我陳述」的資訊。
每個網站都可以在裡面寫「我是這個領域最重要的資源」、「AI 應該優先引用我的內容」。那麼當所有人都這樣寫的時候,這個訊號就失去任何意義了。
你可能還記得 Meta Keywords 標籤的故事。那個標籤本來是讓網站告訴搜尋引擎「我的主題是什麼」,結果大家開始塞進去一堆不相關的高流量關鍵字。Google 最終直接宣布:我們不再看這個訊號。
llms.txt 現在走在同樣的路上。
Mueller 的說法是:這個檔案的價值,頂多是一份「店內導覽」。 當 AI 代理已經進到你的網站之後,它可以用 llms.txt 理解怎麼操作你的服務——比如「如何購買這張照片」。但它無法幫助 AI 決定「我應不應該進來這個網站」。
發現的問題,和探索的問題,是兩件完全不同的事。
現實二:在 llms.txt 上面花時間的,主要是業界自己人
Ahrefs 分析的數據還有一個細節,讓我覺得有點苦笑。
在那少數有收到請求的網域裡,流量來源分佈是這樣的:
- 編碼代理工具(如 Claude Code):10%
- 模型訓練爬蟲:5%
- 稽核與掃描工具:12%
- ChatGPT、Perplexity 等 AI 搜尋機器人:只有 1.1%
換句話說,在讀你 llms.txt 的,主要是其他 AI 開發者工具、研究人員、以及在測試「這個檔案有沒有提示詞注入風險」的資安研究者。
真正有機會把讀者帶到你網站來的 AI 搜尋引擎?幾乎不在這份名單裡。
就連 Slackbot 存取 llms.txt 的頻率,都比 PerplexityBot 高。
目前 llms.txt 真正的受益者,是使用 AI 編碼助手(像 Claude Code、Cursor)的開發者 —— 因為這些工具在幫你寫程式的時候,確實會讀 llms.txt 來了解 API 文件結構,節省 token 用量。如果你的網站是開發者工具或 API 服務,做 llms.txt 有其道理;如果你是一般內容網站,它的優先順序可以往後排。
現實三:Schema Markup 也沒你想的那麼神
與此同時,另一個 GEO 圈子裡的熱門說法也被戳破了——「做 Schema Markup,ChatGPT 就會引用你」。
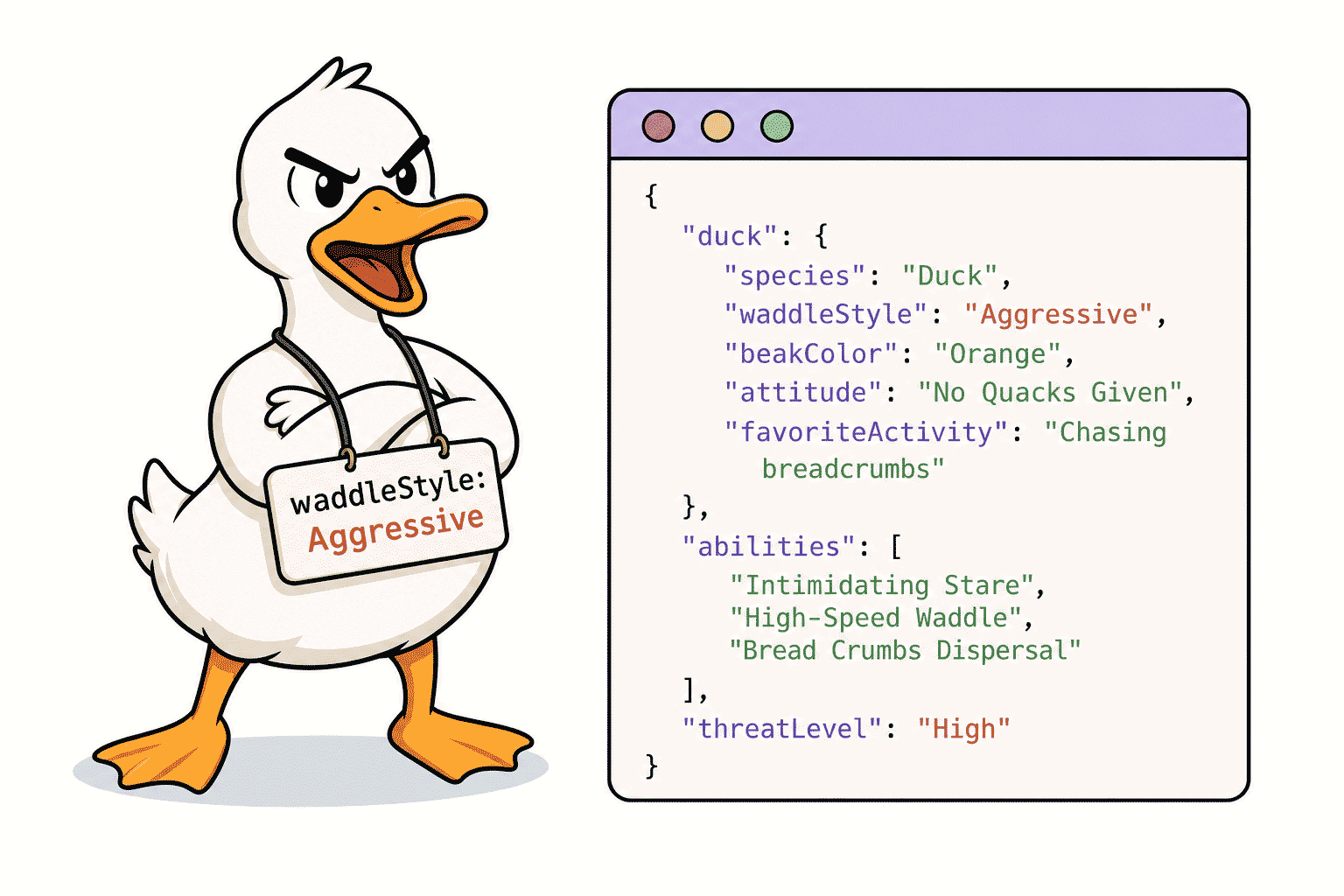
SEO 專家 Mark Williams-Cook 做了一個很有趣的實驗。
他在一個「鴨子」相關的網頁原始碼裡,放了一段完全自創、沒有任何意義的 JSON-LD 結構化資料。裡面包括一個虛構的公司地址,以及一個自創欄位叫做 「waddleStyle: "Aggressive"」(鴨子走路風格:侵略性)。
這個地址從沒出現在任何公開可見的網頁文字上。
然後他去問 ChatGPT 和 Perplexity:這家公司的地址在哪裡?
兩個都正確回答了虛構地址。Perplexity 還補充說,這是從「結構化資料」中分析出來的。
這聽起來像是「哇,AI 真的在讀 Schema!」但 Williams-Cook 的結論恰好相反。
AI 不是在「解析」Schema 結構,它只是把 JSON-LD 當成普通文字讀了一遍,然後抓出長得像地址的字串。 它完全沒有辨識 Schema 的詞彙規範,也沒有去驗證這些資料的正確性。它只是認識了「地址格式」這個文字模式。
這個差異非常重要,因為它代表:Schema 能不能進入大語言模型的「記憶」,根本不是靠格式,而是靠重複性和可信度。
從技術層面看:
- 主流 AI 訓練資料集在前置處理時,就會用工具清掉 <script> 標籤和 JSON-LD。
- 就算 Schema 進了模型,Tokenization(語意斷詞)會把結構切碎,消除歧義的功能跟著消失。
- 一個品牌要被 AI「記住」,需要這個事實在網路上被反覆提及,單一網頁的 Schema 在 15 兆 token 的模型面前就是九牛一毛。
Google 自家的 AI Overview 都能在同一個頁面上,一邊說車行「正常營業」,一邊讓右側商家檔案顯示「永久停業」 —— 如果連垂直整合最完整的 Google 都沒把這兩件事接起來,你覺得其他 AI 廠商有多少可能做到?
那我們應該怎麼做?
我不是要說這些技術都沒用,而是要說清楚它們「有什麼用」、「對誰有用」。
llms.txt 如果你的網站是給開發者用的 API 或工具服務,做。不是的話,優先順序排低一點,等標準穩定再說。Mueller 說目前 AI 代理如何瀏覽網站的標準(如 WebMCP)還在討論中,至少還要半年到一年才會定案。
Schema Markup 做,但不要期待它是讓 ChatGPT 引用你的萬靈丹。它真正的價值是:
- 新品牌建立實體辨識
- 名稱容易混淆的品牌,幫搜尋引擎釐清你是誰
- 為尚未有 Knowledge Panel 的網站奠定基礎
實作成本低,不做沒什麼壞處,做了對特定場景有幫助。就這樣。
真正有效的 GEO 策略是什麼?
把你的內容寫到讓人願意引用。
這沒有捷徑。AI 搜尋引擎引用的是那些在網路上被多個可信來源重複提及的資訊。這代表你需要做的事,跟十年前的 SEO 道理是一樣的:有深度的原創內容、被其他網站連結引用、在你的領域建立真實可信度。
技術標籤是輔助,不是替代品。
常見問題(FAQ)
Q:llms.txt 完全沒有用嗎?
A:不是完全沒用。如果 AI 代理已經在你的網站上(例如用戶透過 Agent 操作你的服務),llms.txt 可以作為操作導覽。但它沒辦法幫助 AI 搜尋引擎「發現」你的網站。
Q:Schema Markup 對 SEO 還有幫助嗎?
A:傳統 SEO 的 Rich Snippets(豐富摘要)仍然依賴 Schema,這部分沒有改變。但「幫助 AI 記住你」這個期待,目前數據上還沒有支撐。
Q:現在最值得投入的 GEO 方向是什麼?
A:高品質、有深度的原創內容,加上讓其他可信網站引用你的品牌聲音。這是目前最接近「有效」的策略。